Introduction
In the article, Big Data Handled Using Apache Hadoop, I looked at what is Hadoop and how it is used to handle Big Data. In conclusion I noted that Hadoop is an aggregation of different modules whose purpose is to store and process Big Data in an efficient and secure manner. One of the modules that can be used on top of Hadoop is Apache Spark. In this article, which is first of many series to come on Spark Apache, I am going to look at a high level overview of what Apache Spark is.
What is Apache Spark ?
Spark, an open source project, is a fast, general purpose cluster computing platform that takes advantage of parallelism, by distributing processing across a cluster of nodes, in order to process data very fast. What make Spark process data fast is the fact that it does the processing in main memory of the worker nodes and in doing so it prevents the unnecessary input and output operations with the disks. According to Apache Spark documentation, Spark is capable of running programs up to 100x faster than Hadoop MapReduce in memory or 10x faster on disk.
Matei Zaharia gave birth to Spark in 2009 as a project within the AMPLab at the University of California, Berkeley. Spark was later on donated to Apache in 2013 and then got promoted as a Top-Level Apache Project in 2014. Spark is one of the most active projects managed by Apache, with more than 500 contributors from across 200 organizations responsible for code and a user base of 225 000+ members. Among the contributors are well-funded corporates such as IBM, Databricks and China’s Huawei.
Spark’s Architecture
Spark comes with a very advanced Direct Acyclic Graph (DAG) data processing engine. On top of that engine, Spark has a stack of domain specific libraries that provide different functionalities useful for different big data processing needs, as shown by the diagram below:
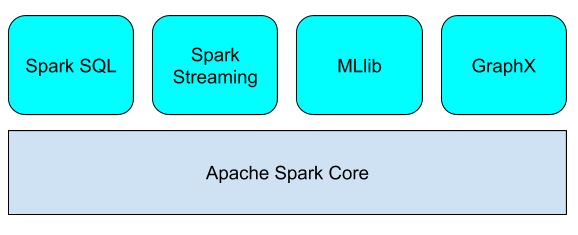
- Spark SQL enables the use of SQL statements inside Spark applications.
- Spark Streaming enables processing of live data streams.
- Spark MLlib enables development of machine learning applications.
- Spark GraphX enables graph processing and supports a growing library of graph algorithms.
Spark can run in:
- a standalone mode on a single node having a supported OS.
- a cluster mode on either Hadoop YARN or Apache Mesos.
- the Amazon EC2 cloud as well and on Kubernetes (an open source system for automating deployment, scaling and management of containerized applications).
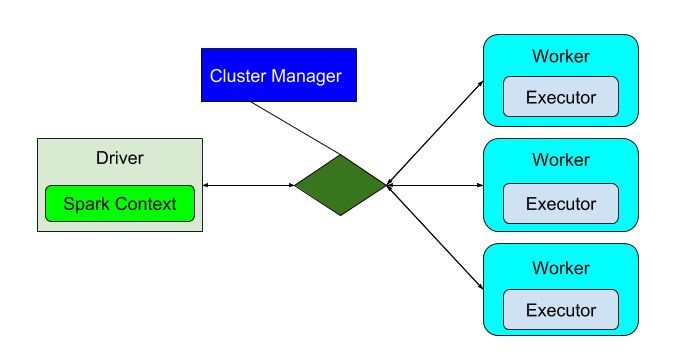
In a distribution application, just like Spark, there is a driver program that controls the execution and there will be one or more worker nodes. The driver program allocates the tasks to the appropriate workers. In Spark, the Spark Context is the driver program and it communicates with the appropriate cluster manager (and this can either be YARN, standalone or Mesos), to run the tasks, as shown below:
Conclusion
This is just a high overview of what Apache Spark is and its high level architecture. In the next series, will take a deep dive into Apache Spark.
Source:
Apache Spark Docs
Apache Spark Architecture Explained