Introduction
In the article, Big Data, what does it mean?, I spoke about what Big Data is and its characteristics. Upon conclusion, we noticed that there are technologies that are used to handle Big Data and that one of those technologies is Hadoop. In this article we will look at what Hadoop is used and a high overview of how it is used to handle Big Data based on the research I did online and what I understood.
What is Hadoop?
In order to understand what Hadoop is, one needs to understand the problem Hadoop is trying to address, and that problem is Big Data. We now know that Big Data is characterized by the 3 Vs, volume, velocity and variety. There is need to store huge amounts of data, in its different forms, and that cannot be done on a single computer. There is also need to process that huge amount of data and again it cannot be handled by a single computer using the traditional software we already have.
Lets use a hypothetical scenario in order to understand what Hadoop is. There is a bumper harvest on a farm and there is need for storage of the harvest, say wheat. Now a single silo will not be able to store all the wheat and there is need for more than one silo, say 24 is needed. All the wheat is harvested and stored nicely in the silos. Now the wheat needs to be processed so that the farmer can produce flour for baking. To process one silo takes about, say 24 hours, that is one day. For all silos, that will take 24 days and the farmer’s clients are already waiting for the flour to be supplied and they cannot wait for 24 days. The farmer then employs a more advanced machinery that can process more wheat and takes less time, say for one silo it now takes 4 hrs. If my math is right, one machine will take 4 days to process all the silos, but this needs to be done in one day, so the farmer buys 3 more machines. All is good, the wheat is processed in a day and the following day all the flour has been packaged and is ready for delivery. All this is summarized below:
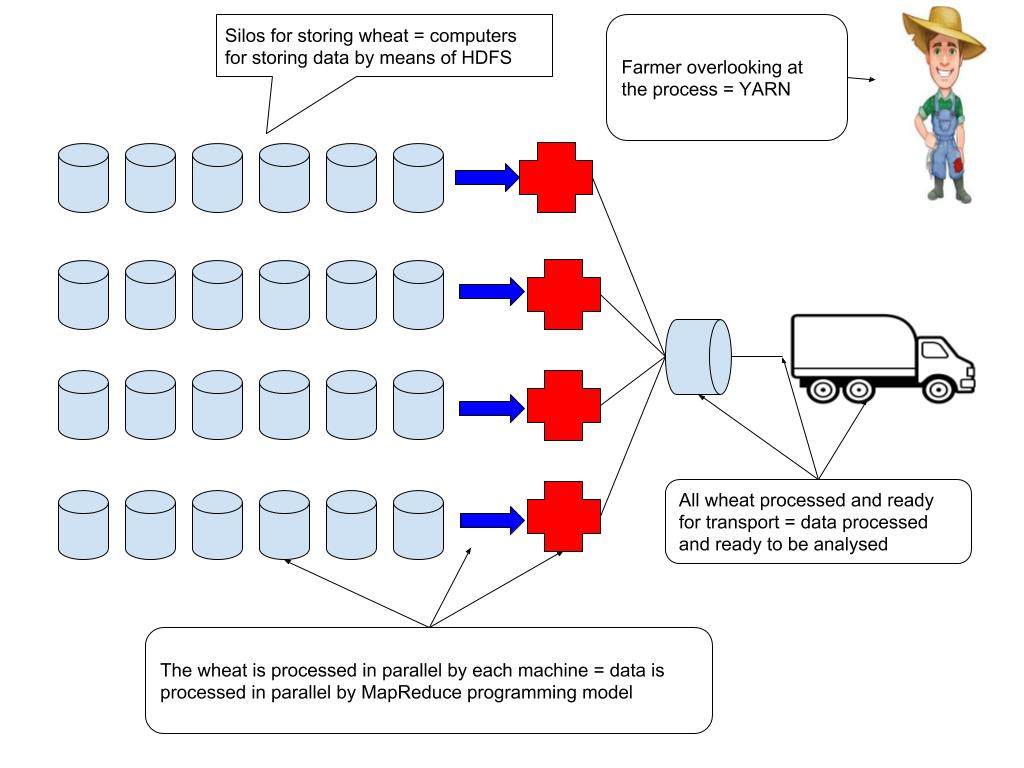
Wheat can be thought of as data that needs to be stored and one silo will not do. The same with data, one computer will not be sufficient and hence we need a number of computers. A collection of computers whose purpose is to store data and process it is known as a cluster and each computer on that cluster is known as a node. The wheat can be thought of as being distributed to each silo. This is the same with data, it is distributed among the computers and in Hadoop it is achieved using its distributed flies system known as Hadoop Distributed File System, HDFS in short. The wheat again is processed in parallel so that flour can be produced in a day. This is the same with data, it can be processed in parallel so that whatever computation is done can produce results faster. In Hadoop this is done using a MapReduce programming model. For the machines to operate smoothly, the farmer needs to overlook at the whole process and in Hadoop that is done using YARN short for Yet Another Resource Negotiator.
Hadoop, an Apache open-source project, is therefore a combination of modules whose purpose is to store and process huge amounts of data. At the core of Hadoop, there is HDFS, responsible for storing the data and MapReduce, responsible for processing the data. In addition to the core there is Hadoop YARN and Hadoop Common. The modules are summarized as follows:
Hadoop Distributed File System (HDFS) is a distributed file system that stores data on commodity machines, providing very high aggregate bandwidth across the cluster.
Hadoop MapReduce is an implementation of the MapReduce programming model for large scale data processing.
Hadoop YARN is a platform responsible for managing computing resources in a cluster and using them for scheduling applications.
Hadoop Common contains libraries and utilities needed by other Hadoop modules.
Back to our farm analogy, if the farmer wants to keep say chickens for poultry farming, the farmer will build a poultry cage on the very same land where wheat is grown and kept. The farmer can do more than one activity on the farm, the limit here is the size of land and talent. Same thing with Hadoop. It is not limited to the aforementioned modules, but other modules can be added onto the platform such as Hive, HBase, Zookeeper, Kafka, Storm, Spark and so forth. All these modules perform different functions.
How it began
The co-founders of Hadoop are Doug Cutting and Mike Cafarella. The name Hadoop, came from Doug’s son’s toy elephant. Doug and Mike were inspired by the “Google File System” paper that was published in October 2003. The initial development was on the Apache Nutch project but later on moved to the new Hadoop project in January 2006. The first committer to add to the Hadoop project was Owen O’Malley in March 2006 and Hadoop 0.1.0 was released in April 2006. It continues to evolve through the many contributions that are being made to the project.
Conclusion
This was just a high overview of what Hadoop is and how it handles Big Data. From this, in short, we can say Hadoop is an aggregation of different modules wholes purpose is to store and process Big Data in an efficient and secure manner. In future articles, I will look into the core modules of Hadoop in depth.
Source:
Wiki Apache Hadoop