Introduction
In this post I am going to talk about an exception I got when I was trying to read data from Hive using Spark and how I managed to debug the issue and resolved it. I will also explain how one can reproduce the issue, by doing so, one can also avoid reproducing it. The exception was:
java.lang.ClassCastException: org.apache.hadoop.io.Text cannot be cast to org.apache.hadoop.hive.serde2.io.DateWritable
Spark code
Here is the snippet of the code that I had in spark:

From the code snippet above, all I am doing is a simple select from a table called geonames_data which is in a database called tendai_test and I just want to read only 5 records. The exception is thrown when trying to retrieve the data using the show function.
Debugging
Now, my first instinct was to check the schema of the table. Using the Dataframe’s printSchema function, I can see the fields and their datatypes as shown below:
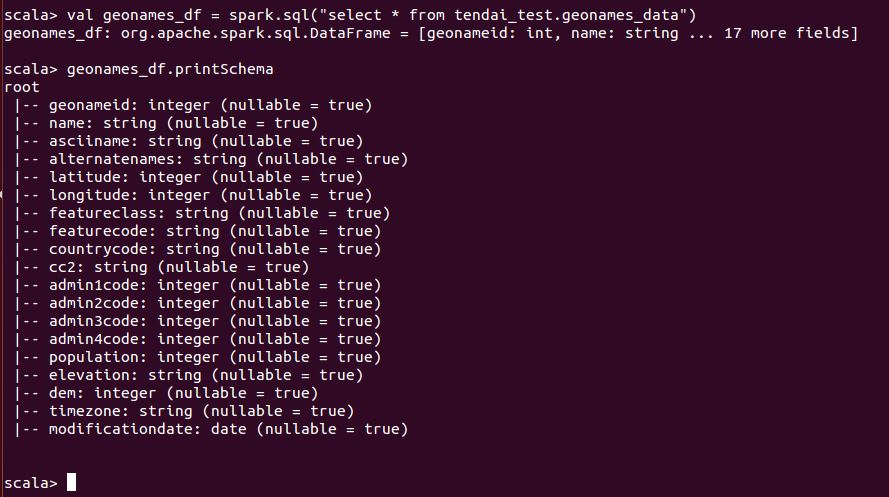
From the schema above I can see that all the fields and their datatypes and all is what I expect. However, from the query I am using to retrieve the data, there is no place I am doing a cast. Therefore, there got to be another place I need to check to see if there is a difference. The next place I checked was to read the schema from ORC as shown below:
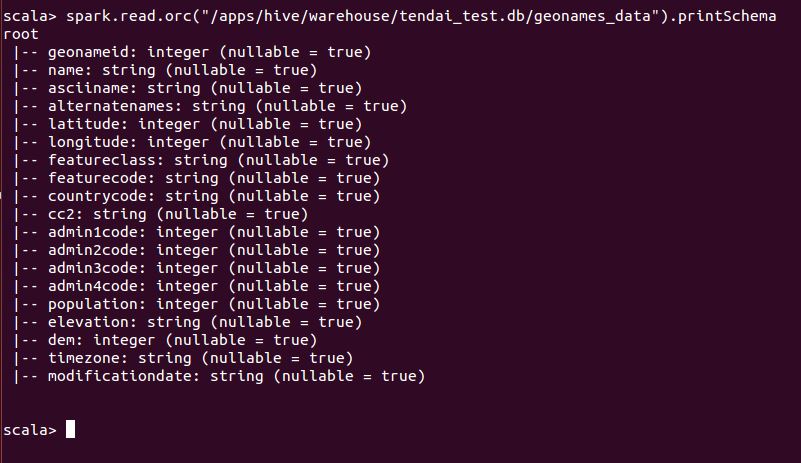
From the schema above, I noticed that there is a difference in datatypes for a field called modificationdate, from ORC its string whereas from Hive its a date.
Solution
Quick solution is to do a backup of the table in Hive as follows:
create table tendai_test.geonames_data_backup as select * from tendai_test.geonames_data;
After backing up the data, drop the original table as follows:
drop table tendai_test.geonames_data purge;
Once the table is dropped, create the table using the original script and using the geonames_data table, the script is as follows:
create table tendai_test.geonames_data(
geonameid int,
name string,
asciiname string,
alternatenames string,
latitude int,
longitude int,
featureclass string,
featurecode string,
countrycode string,
cc2 string,
admin1code int,
admin2code int,
admin3code int,
admin4code int,
population int,
elevation string,
dem int,
timezone string,
modificationdate date)
STORED AS ORC;
Once that is done, populate the table using the backed up data from geonames_data_backup as follows:
insert into tendai_test.geonames_data select * from tendai_test.geonames_data_backup;
Back to the Spark code
If I run the Spark code again, I will no longer have the exception as shown below:
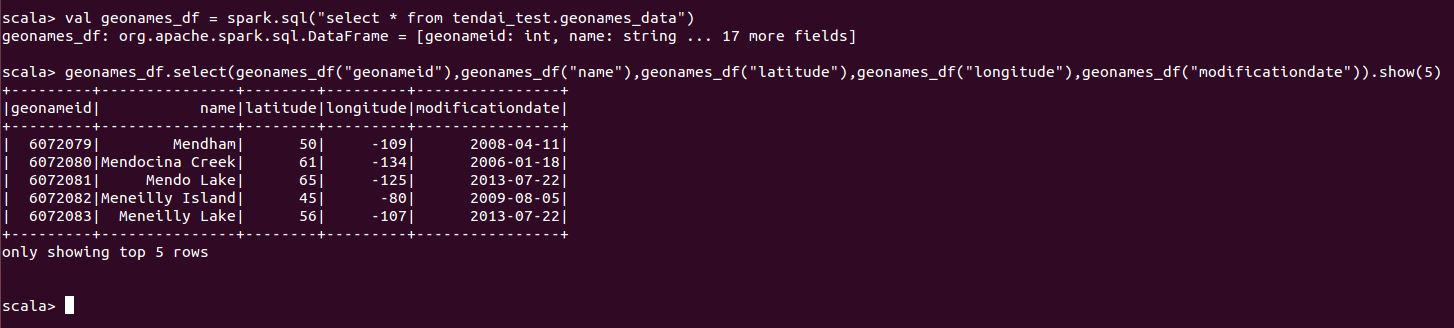
Just did a minor modification to the code by selecting a few fields.
Reproducing the issue
Using the backup table from the above, we can recreate the issue as follows:
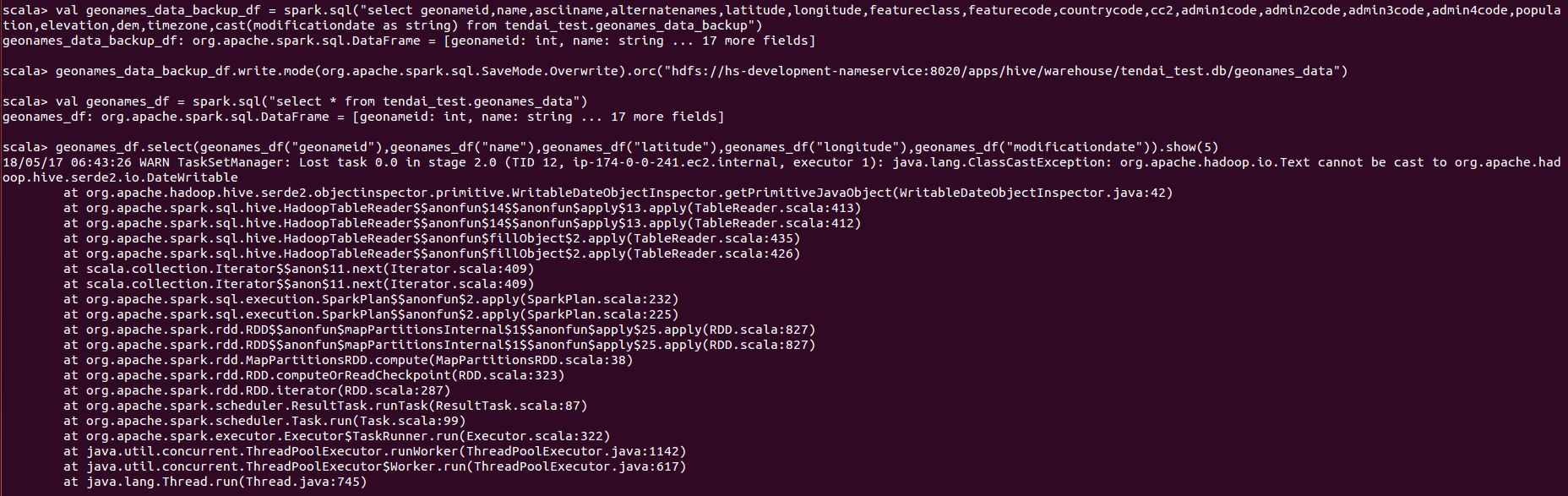
Lessons
The lesson here is that, when writing data in Spark, make sure that the datatypes are not changed. Or when doing a cast, make sure that the cast is of the right datatype. Check first before doing a cast to make sure that the right thing is being done.
Doing this without checking might slow down production especially if working in a big team. Say someone is reading data from geonames_data, and the expected datatype of modificationdate is date, then all of a sudden there is now a cast exception. Trying to get to the bottom of the issue and resolving it, will slow down progress.
Conclusion
This is what I experienced and I just wanted to share. In future posts, I will talk about Hive since there are some concepts in this post that I didn’t talk about, for instance ORC and Dataframes.